并非所有数据都是平等的。但是任何一条数据可能包含多少信息呢?这个问题对于医学测试、设计科学实验,甚至对于人类日常学习和思考都至关重要。麻省理工学院的研究人员开发了一种新的方法来解决这个问题,在医学、科学发现、认知科学和人工智能方面开辟了新的应用。
从理论上讲,已故麻省理工学院名誉教授克劳德·香农在1948年发表的论文“通信的数学理论”明确地回答了这个问题。香农的突破性成果之一是熵的概念,它使我们能够量化任何随机对象中固有的信息量,包括模拟观察数据的随机变量。香农的成果奠定了信息论和现代电信的基础。熵的概念也被证明是计算机科学和机器学习的核心。
估计熵的挑战
不幸的是,香农公式的使用很快就会变得难以计算。它需要精确计算数据的概率,这反过来又需要计算数据在概率模型下可能出现的所有可能方式。如果数据生成过程非常简单——例如,单次抛硬币或掷骰子——那么计算熵就很简单了。但是考虑医学检测的问题,阳性检测结果是数百个相互作用变量的结果,这些变量都是未知的。只有10个未知数,数据已经有1000种可能的解释。有几百个,可能的解释比已知宇宙中的原子还要多,这使得计算熵完全是一个难以解决的问题。
麻省理工学院的研究人员开发了一种新方法,通过使用概率推理来估计许多信息量(例如香农熵)的良好近似值。这项工作出现在作者FerasSaad博士在AISTATS2022上发表的一篇论文中。电气工程和计算机科学的候选人;Marco-CusumanoTowner,博士;和VikashMansinghka博士,脑与认知科学系的首席研究科学家。关键的见解是,而不是枚举所有解释,而是使用概率推理算法首先推断哪些解释是可能的,然后使用这些可能的解释来构建高质量的熵估计。该论文表明,这种基于推理的方法可以比以前的方法更快、更准确。
在概率模型中估计熵和信息从根本上说是困难的,因为它通常需要解决高维积分问题。许多以前的工作已经为某些特殊情况开发了这些量的估计器,但是通过推理的熵的新估计器(EEVI)提供了第一种方法,可以在广泛的信息理论量上提供明确的上限和下限。上下界意味着虽然我们不知道真正的熵,但我们可以得到一个小于它的数和一个大于它的数。
“由于三个原因,我们的方法提供的熵的上限和下限特别有用,”Saad说。“首先,上限和下限之间的差异给出了我们应该对估计有多大信心的定量感觉。其次,通过使用更多的计算工作,我们可以将两个界限之间的差异推向零,这“挤压”了真实的“第三,我们可以组合这些界限来形成对许多其他数量的估计,这些数量告诉我们模型中不同变量之间的信息量。”
使用数据驱动的专家系统解决基本问题
Saad说,他对这种方法在机器辅助医疗诊断等领域查询概率模型的可能性感到最兴奋。他说,EEVI方法的一个目标是能够使用丰富的生成模型来解决新的查询,这些模型已经由医学领域的专家开发,用于肝病和糖尿病等疾病。例如,假设我们有一个患者具有一组观察到的属性(身高、体重、年龄等)和观察到的症状(恶心、血压等)。鉴于这些属性和症状,EEVI可用于帮助确定医生应针对症状进行哪些医学检查,以最大限度地了解特定肝病(如肝硬化或原发性胆汁性胆管炎)是否存在。
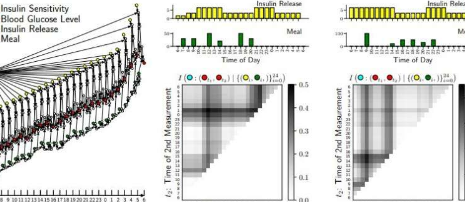
对于胰岛素诊断,作者展示了如何使用计算最佳时间的方法来进行血糖测量,从而最大限度地了解患者的胰岛素敏感性信息,并给出专家构建的胰岛素代谢概率模型和患者的个性化膳食和药物时间表。随着血糖监测等常规医疗跟踪从医生办公室转向可穿戴设备,如果可以提前准确估计数据的价值,那么改进数据采集的机会就会更多。
该论文的资深作者VikashMansinghka补充说:“我们已经证明,概率推理算法可用于估计AI工程师通常认为难以计算的信息度量的严格界限。这开辟了许多新的应用。它还表明推理可能比我们想象的更具有计算基础。它还有助于解释人类大脑如何能够如此普遍地估计信息的价值,作为日常认知的核心组成部分,并帮助我们设计具有这些能力。”
在AISTATS2022上发表了论文“通过概率模型中的推理来估计熵和信息”。















